Introduction
When a User Equipment(UE) is powered on or when it enters a new cell, it must be able to find the cell and synchronize to it in frequency and time. It must also be able to read some system information describing the cell in order to see if it can be used by the UE.
5G NR uses below synchronization signals:
- Primary Synchronization Signal, PSS, with 3 different code sequences
- Secondary Synchronization Signal, SSS, with 336 different code sequences
These signals enable the UE to find a cell along with helping it in synchronizing to the cell’s timing. There can be 1008 (3 X 336) possible code sequences and the value in the PSS/SSS determines cell’s Physical Cell Identity (PCI). When the UE finds these synchronization signals, it can also read the Physical Broadcast Channel (PBCH), whose location can be found around these synchronization signals.
Cell search also covers the functions and procedures by which a device finds new cells. The procedure is carried out when a device is initially entering the coverage area of a system. To enable mobility, cell search procedure is also continuously carried out by devices moving within the system, both when the device is connected to the network and when in idle/inactive state.
Cell Search in Standalone Mode
In order to perform the initial cell access in the Standalone (SA) mode, a UE need to perform Contention Based Random Access procedure (CBRA) and therefore it needs to acquire the relevant system information, which is System Information Block1 (SIB1). Accessing this information requires acquisition of Master Information Block (MIB) and it’s decoding. This is only possible while detecting and identifying the synchronization signal block. However, no information is provided in the SA mode to find the frequencies where the SSBs are transmitted, unlike Non-Standalone (NSA) mode where the UE receives the exact frequency location of the SSB via dedicated RRC signaling over the established LTE connection.
Synchronization Signal Block
A synchronization signal block (SSB) consists of one OFDM symbol for the PSS and one OFDM symbol for the SSS. Furthermore, the SS block may contain two OFDM symbols for the PBCH which are identical. So, the SS block spans four OFDM symbols in the time domain and 240 subcarriers in the frequency domain. PSS is transmitted in the first OFDM symbol of the SS block and occupies 127 subcarriers in the frequency domain. The remaining subcarriers are empty. SSS is transmitted in the third OFDM symbol of the SS block and occupies the same set of subcarriers as the PSS. There are eight and nine empty subcarriers on each side of the SSS. PBCH is transmitted within the second and fourth OFDM symbols of the SS block. In addition, PBCH transmission also uses 48 subcarriers on each side of the SSS. The total number of resource elements used for PBCH transmission per SS block thus equals 576, which includes resource elements for the PBCH along with resource elements for the demodulation reference signals (DMRS) needed for coherent demodulation of the PBCH.

The synchronization signals and the physical broadcast channel within a synchronization signal block are time multiplexed. Below fig. shows another way of representing structure of SSB.

One important difference between the SS block and the corresponding signals for LTE is the possibility to apply beam-sweeping for SS-block transmission i.e. the possibility to transmit SS blocks in different beams in a time-multiplexed fashion.
The timing of the SS Block can be set by the network operator. Default value of SSB transmission is 20ms but can be set between 5 and 160ms (5, 10, 20, 40, 80 and 160). During this time set by the operator, a number of SS Blocks will be transmitted in different directions (called Beams) during a 5ms Period. Each block of transmitted SS Blocks is referred to as an SS Burst Set. Although the periodicity of the SS burst set is flexible with a minimum period of 5ms and a maximum period of 160ms, each SS burst set is always confined to a 5ms time interval, either in the first or second half of a 10ms frame. Below example shows the default setting of 20ms.
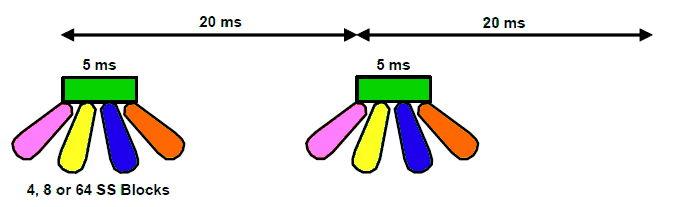
By applying beamforming for the SS block, the coverage of a single SS block transmission gets increased. Beam-sweeping for SS-block transmission also enables receiver-side beam-sweeping for the reception of uplink random-access transmissions as well as downlink beamforming for the random-access response
Now, the 20ms SS-block periodicity is four times longer than the corresponding 5ms periodicity of LTE PSS/SSS transmission. The longer SS-block period was selected to allow for enhanced NR network energy performance and in general to follow the ultra-lean design paradigm. The drawback with a longer SS-block period is that a device must stay on each frequency for a longer time in order to conclude that there is no PSS/SSS on the frequency. However, this is compensated for by the sparse synchronization raster which reduces the number of frequency-domain locations on which a device must search for an SS block.
SS Blocks can be sent over 4, 8 or 64 beams in a cell. The lower numbers will be used for lower frequencies as there will be a smaller number of antennas for such configuration. The SS Blocks will be used as follows:
- 4 SS Blocks: used for frequency range 1 below 3 GHz
- 8 SS Blocks: used for frequency range 1 between 3 and 6 GHz
- 64 SS Blocks: used for frequency range 2
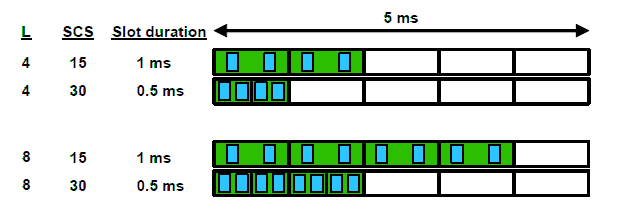
As per specifications, there can be different cases for the SS Block transmission. These cases cover different sub carrier spacings along with normal or extended cyclic prefix if the subcarrier spacing used is 30KHz. These cases are depicted below in the fig:

As you would have noticed, 60KHz subcarrier spacing is not included in above cases since it can’t carry any SS Blocks. Also, note that an SS Block is always distributed over 20 resource blocks in frequency domain. The size of the SS Block in the frequency domain will scale as per the subcarrier spacing used. Not all slots can be used for transmission of the block during the 5ms period when SS block can be transmitted. The number of slots used will also depend on the number of transmissions (4, 8 or 64) during the 5ms period. Below fig shows the possible transmission of SS Blocks for the case of 4 and 8 transmission times per 5ms period (depicted by the ‘L’ parameter in below fig)
Difference between LTE and NR Cell Search Approach
In LTE, synchronization signals were located in the center of transmission BW so once an LTE device has found a PSS/SSS i.e. found a carrier, it inherently knows the center frequency of the found carrier. The drawback was that a device with no prior knowledge of the frequency-domain carrier position must search for PSS/SSS at all possible carrier positions (the “carrier raster”). So, a different approach has been adopted in 5G, to allow for faster cell search. In 5G, the signals are not fixed, rather located in a synchronization raster (a more limited set of possible locations of SS block within each frequency band). Instead of searching for an SS block at each position of the carrier raster, a device only needs to search for an SS block on the sparse synchronization raster. When found, the UE gets informed on where in frequency domain it is located.
Also, LTE used a concept of 2 synchronization signals with a fixed format which enabled UEs to find a cell. 5G NR also uses 2 synchronization signals but the difference is the support of beamforming and reduction in the number of “Always on” signals.
PSS and SSS
PSS is the first signal that a device entering the system will search for. At that stage, the device has no knowledge of the system timing. Once the device has found the PSS, it has found synchronization up to the periodicity of the PSS. PSS extends over 127 resource elements and has 3 different PSS Sequences. Physical cell identity (PCI) of the cell determines which of the three PSS sequences to use in a certain cell. When searching for new cells, a device must search for all three PSSs.
Once a device detects a PSS it knows the transmission timing of the SSS. By detecting the SSS, the device can determine the PCI of the detected cell. There are 1008 (3 X 336) different PCIs. However, already from the PSS detection the device has reduced the set of candidate PCIs by a factor 3. There are thus 336 different SSSs, that together with the already-detected PSS provides the full PCI. The basic structure of the SSS is same as that of the PSS i.e. the SSS consists of 127 subcarriers to which an SSS sequence is applied.
PBCH
While the PSS and SSS are physical signals with specific structures, PBCH is a more conventional physical channel on which explicit channel-coded information is transmitted. PBCH carries the MIB, which contains information that the device needs in order to be able to acquire the remaining SI broadcast by the network.
Below table shows the information carried by the PBCH:
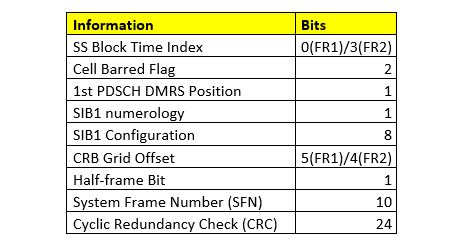
- SS-block time index identifies the SS-block location within an SS burst set. Each SS block has a well-defined position within an SS burst set which is contained within the first or second half of a 5ms frame. From the SS-block time index, in combination with the half-frame bit, the device can determine the frame boundary. The SS-block time index is provided to the device as two parts:
- 1st part encoded in the scrambling applied to the PBCH
- 2nd part included in the PBCH payload.
For operation in higher NR frequency range (FR2), there can be up to 64 SS blocks within an SS burst set, implying the need for 3 additional bits to indicate the SS-block time index. These 3 bits are only needed for operation above 10 GHz and are included as explicit information within the PBCH payload.
- CellBarred flag consist of two bits where 1st bit is the actual CellBarred flag that indicates whether devices can access the cell or not. Assuming devices are not allowed to access the cell, the 2nd bit, also referred to as the Intra-frequency-reselection flag, indicates whether access is permitted to other cells on the same frequency or not.
- 1st PDSCH DMRS position indicates the time-domain position of the first DMRS symbol assuming DMRS Mapping Type A
- SIB1 numerology provides info about the subcarrier spacing used for the transmission of the SIB1. The same numerology is also used for the downlink Message 2 and Message 4 that are part of the random-access procedure.
- SIB1 configuration provides info about the search space, corresponding CORESET, and other PDCCH-related parameters that a device needs in order to monitor for the scheduling of SIB1.
- CRB grid offset provides info about the frequency offset between the SS block and the common resource block grid. Information about the absolute position of the SS block within the overall carrier is provided within SIB1.
- Half-frame bit indicates if the SS block is located in the 1st or 2nd 5ms part of a 10ms frame.
Acquiring System Information
When the UE has found the SS Block, it can read the PBCH which contains MIB. When the MIB has been decoded by the UE, it can start to search for SIB1. When SIB1 has been found and read, all remaining SIBs are decoded or requested.
In LTE, all system information was periodically broadcast over the entire cell area making it always available but also implying that it is transmitted even if there is no device within the cell. 5G NR, on the other hand, adopted a different approach where the system information, beyond the very limited information carried within the MIB, has been divided into two parts: SIB1 and the remaining SIBs.
SIB1 which is sometimes also referred to as the remaining minimum system information (RMSI) consists of the system information that a device needs to know before it can access the system. SIB1 is always periodically broadcast over the entire cell area. One important task of SIB1 is to provide the information the device needs in order to carry out an initial random access. SIB1 is provided by means of ordinary scheduled PDSCH transmissions with a periodicity of 160ms. The PBCH/MIB provides information about the numerology used for SIB1 transmission as well as the search space and corresponding CORESET used for scheduling of SIB1. Within that CORESET, the device then monitors for scheduling of SIB1 indicated by a special System Information RNTI (SI-RNTI).
In 5G a UE can request for other system information with a RACH procedure, as compared to the traditional mobile networks, where all other system information (SIB =>) is broadcasted. Below is the terminology that is used in 5G for the system information:
- Minimum System Information
- Master Information Block (MIB)
- System Information Block1 (SIB1)
- Other System Information
- System Information Block 2 to 9 (SIB2 to SIB9)

Minimum SI is always broadcasted in the whole cell. When Beamforming is used, the information is transmitted in all the beams. If a UE can’t decode the minimum SI, it should regard the cell as barred for access or camping.
Note: Small micro or Pico cells may not be used for initial access so the UEs must use a large macro cell for access and camping. The smaller cells may only be activated on demand when the traffic is high.
Other SI can be broadcasted but not always. This can be used in larger cells with high traffic.
As mentioned earlier, it is possible to request the other SI on-demand, which can be used in cells with low traffic. To request for the SI, the UE need to perform random access procedure. The network can either reserve dedicated resources for this request, or the UE will indicate the request for other system information in the message sent to the network. This way the network can avoid periodic broadcast of these SIBs in cells where no device is currently camping, thereby allowing for enhanced network energy performance.
Below is the short summary of the information carried by different SIBs:
- SIB1: PLMN identity list, Tracking Area Code, Cell Identity, Barred/not Barred Indication, Cell Selection Information, SI scheduling information, support for emergency call indication, support for IMS voice call indication, timers, constants, barring information
- SIB2: Cell reselection information
- SIB3: Neighboring cells on same frequency (5G)
- SIB4: Neighboring cells on different frequency (5G)
- SIB5: Neighboring LTE cells
- SIB6/7: ETWS information (Earthquake and Tsunami warning system)
- SIB8: CMAS (Commercial Mobile Alert System)
- SIB9: GPS and UTC Time
References:
- “5G NR – The next generation wireless access technology” – By Erik Dahlman, Stefan Parkvall, Johan Sköld
- http://www.techplayon.com/5g-nr-cell-search-and-synchronization-acquiring-system-information/
- http://howltestuffworks.blogspot.com/2019/10/5g-nr-synchronization-signalpbch-block.html